DEMO
Methodology
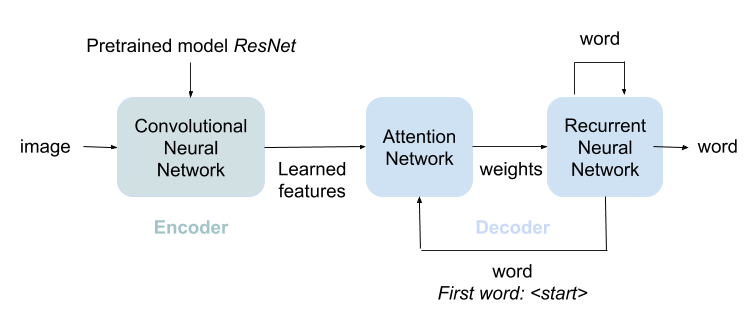
Elisabot is a conversational agent that simulates a reminiscence therapist by asking questions about the patient's experiences. Questions are generated from pictures provided by the patient, which contain significant moments or important people in user's life. The proposed methodology is specific for dementia therapy, compared to a general Image-based Question and Answering (Q&A) system, because the generated questions cannot be answered by only looking at the picture as common Q&A systems do, the user needs to know the place, the time, the people or animals appearing in the picture to be able to answer the questions. The activity pretends to be challenging for the patient, as the questions may require the user to exercise the memory, but amusing at the same time.
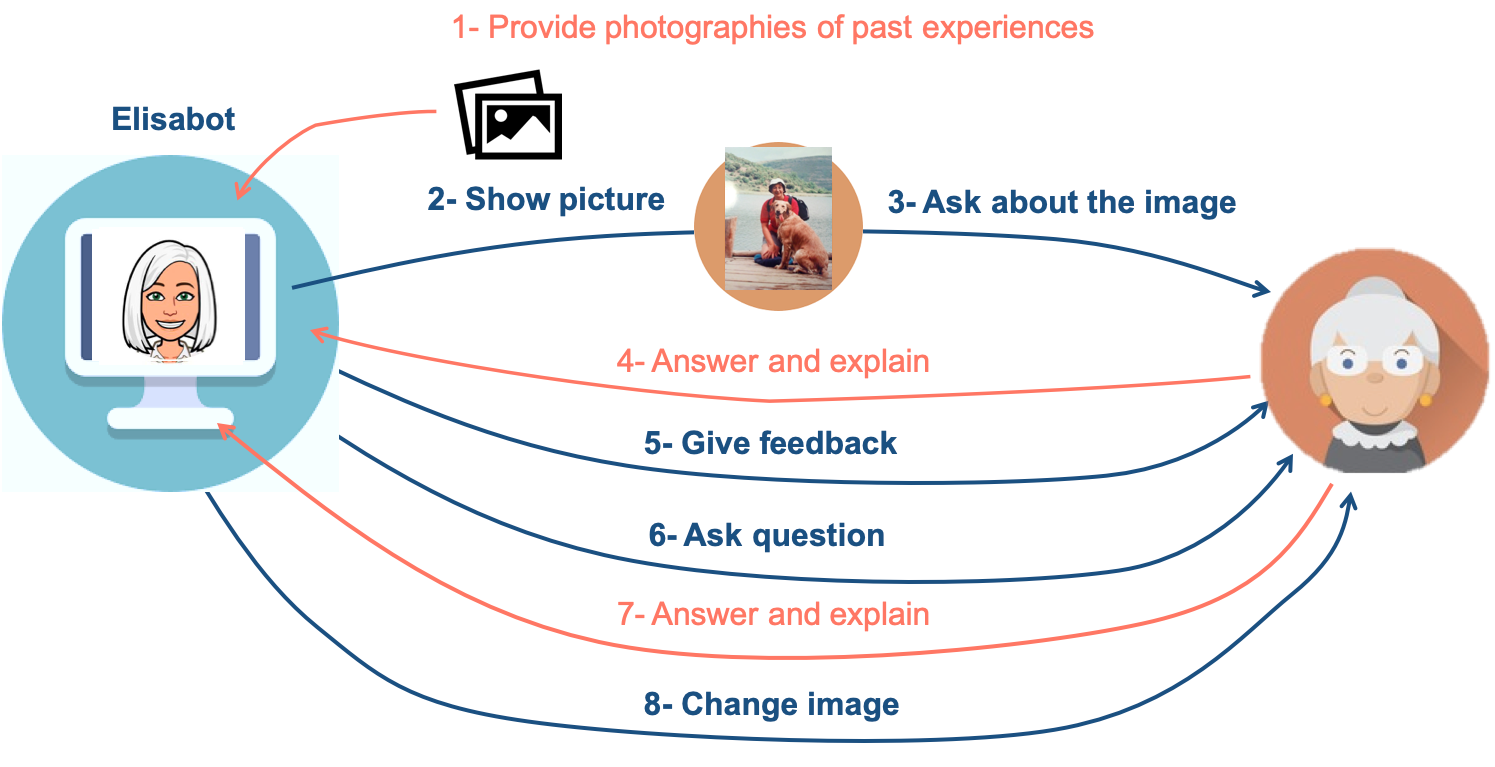
Before starting the conversation, the user must introduce photos containing significant moments for him/her. The system randomly chooses one of these pictures and analyses the content. Then, Elisabot shows the selected picture and starts the conversation by asking a question about the picture. The user should give an answer, even though he does not know it, and Elisabot makes a relevant comment on it. The cycle starts again by asking another relevant question about the image and the flow is repeated for 4 to 6 times until the picture is changed.